Chapter 5 - Optimizing wide networks
In the previous chaper, we proved that (S)GD converges locally for training neural networks with smooth activations. (The case for ReLU networks is harder but still doable with additional algebraic heavy lifting.)
However, in practice, somewhat puzzlingly we encounter very deep networks that are regularly optimized to zero training loss, i.e., they exactly learn to interpolate the given training data and labels. Since loss functions are typically non-negative, this means that (S)GD have achieved convergence to the global optimum.
In this chapter, we ask the question:
When and why does (S)GD give zero train loss?
An answer to this question in full generality is not yet available. However, we will prove a somewhat surprising fact: for very wide networks that are randomly initialized, this is indeed the case. The road to proving this will give us several surprising insights, and connections to classical ML (such as kernel methods) will become clear along the way.
Local versus global minima
Let us bring up this picture from Xu et al.1 again:
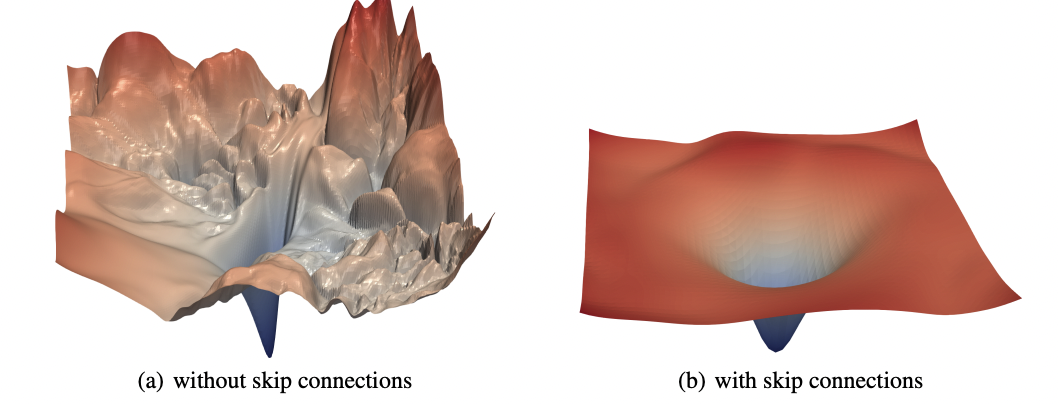
The picture on the left shows the loss landscape of a feedforward convolutional network. The picture on the right shows the loss landscape of the same network with residual skip connections.
Why would (S)GD navigate its way to the global minimum of this jagged-y, corrugated loss landscape? There could be one of many explanations.
-
Explanation 1: We got lucky and initialized very well (close enough to the global optimum for GD to work). But if there is only one global minimum then “getting lucky” is an event that happens with exponentially small probability. So there has to be another reason.
-
Explanation 2: The skips (clearly) matter, so maybe most real-world networks in fact look like the ones on the right. There is a grain of truth here: in modern (very) deep networks, there exist all kinds of bells and whistles to “make things work”. Residual (skip) connections are common. So are other tweaks such as batch normalization, dropout, learning rate scheduling, etc etc. All2 of these3 tweaks4 significantly influence the nature of the optimization problem.
-
Explanation 3: Since modern deep networks are so heavily over-parameterized, there may be tons of minima that exactly interpolate the data. In fact, with high probability, a random initialization lies “close” to a interpolating set of weights. Therefore, gradient descent starting from this location successfully trains to zero loss.
We will pursue Explanation 3, and derive (mathematically) fairly precise justifications of the above claims. As we will argue in the next chapter, this is by no means the full picture. But the exercise is still going to be very useful.
The Neural Tangent Kernel
Our goal will be to understand what level of over-parameterization enables gradient descent to train neural network models to zero loss. So if the network contains $p$ parameters, we would like to derive scaling laws of $p$ in terms of $n$ and $d$. Since the number of parameters is greater than the number of samples, proving generalization bounds will be challenging. But let’s set aside such troubling thoughts for now.
When we think of modern neural networks and their size, we typically associate “growing” the size of networks in terms of their depth. However, our techniques below will instead focus on the width of the network (mirroring our theoretical treatment of network representation capacity). Many results below apply to deep networks, but the key controlling factor is the width (note: actually, not even the width but other strange properties; more later.) The impact of depth will continue to remain elusive.
Here’s a high level intuition of the path forward:
-
We know that if the loss landscape is convex, then the dynamics of training algorithms such as GD or SGD ensures that we always converge to a global optimum.
-
We know that linear/kernel models exhibit convex loss landscapes.
-
We will prove that for wide enough networks, the loss landscape looks like that of a kernel model.
So in essence, establishing the last statement triggers the chain of implications:
\[(3) \implies (2) \implies (1)\]and we are done.
Some history. The above idea is called the Neural Tangent Kernel, or the NTK, approach. The term itself first appeared in a landmark paper by Jacot et al.5, which first established the global convergence of NN training in the infinite-width limit. Roughly around the same time, several papers emerged that also provided global convergence guarantees in certain specialized families of neural network models. See here6, here7, and here8. All of them involved roughly the same chain of implications as described above, so now can be dubbed as “NTK-style” papers.
Gradient dynamics for linear models
As a warmup, let’s first examine how GD over the squared-error loss learns the parameters of linear models. Most of this should be classical. For a given training dataset $(x_i, y_i)$, define the linear model using weights $w$, so that the predicted labels enjoy the form:
\[u_i = \langle x_i, w \rangle, \qquad u = Xw\]where $X$ is a matrix with the data points stacked row-wise. This leads to the familiar loss:
\[L(w) = \frac{1}{2} \sum_{i=1}^n \left( y_i - \langle x_i, w \rangle \right)^2 = \frac{1}{2} \lVert y - Xw \rVert^2 .\]We optimize this loss via GD:
\[w^+ = w - \eta \nabla L(w)\]where the gradient of the loss looks like:
\[\nabla L(w) = - \sum_{i=1}^n x_i (y_i - u_i) = - X^T (y - u)\]and so far everything is good. Now, imagine that we execute gradient descent with infinitesimally small step size $\eta \rightarrow 0$, which means that we can view the evolution of the weights as the output of the following ordinary differential equation (ODE):
\[\frac{dw}{dt} = - \nabla L(w) = X^T (y - u).\]This is sometimes called Gradient Flow (GF), and standard GD is rightfully viewed as a finite-time discretization of this ODE. Moreover, due to linearity of the model, the evolution of the output labels $u$ follows the ODE:
\[\begin{aligned} \frac{du}{dt} &= X \frac{dw}{dt}, \\ \frac{du}{dt} &= XX^T (y-u) \\ &= H (y - u). \end{aligned}\]Several remarks are pertinent at this point:
-
Linear ODEs of this nature can be solved in closed form. If $r = y-u$ is the “residual” then the equation becomes:
\[\frac{dr}{dt} = - H r\]whose solution, informally, is the (matrix) exponential:
\[r(t) = \exp(-Ht) r(0)\]which immediately gives that if $H$ is full-rank with $\lambda_{\text{min}} (H) >0$, then GD is extremely well-behaved; it provably converges at an exponential rate towards a set of weights with zero loss.
-
Following up from the first point: the matrix $H = X X^T$, which principally governs the dynamics of GD, is constant with respect to time, and is entirely determined by the geometry of the data. Configurations of data points which push $\lambda_{\text{min}} (H)$ as high as possible enable GD to converge quicker, and vice versa.
-
The data points themselves don’t matter very much; all that matters is the set of their pairwise dot products:
\[H_{ij} = \langle x_i, x_j \rangle .\]This immediately gives rise to an alternate way to introduce the well-known kernel trick: simply replace $H$ by any other easy-to-compute kernel function:
\[K_{ij} = \langle \phi(x_i), \phi(x_j) \rangle\]where $\phi$ is some feature map. We now suddenly have acquired the superpower of being able to model non-linear features of the data. This derivation also shows that training kernel models is no more challenging than training linear models (provided $K$ is easy to write down.)
Gradient dynamics for general models
Let us now derive the gradient dynamics for a general deep network $f(w)$. We mirror the above steps. For a given input $x_i$, the predicted label obeys the form:
\[u_i = f_{x_i}(w)\]where the subscript of $f$ here makes the dependence on the input features explicit. The squared-error loss becomes:
\[L(w) = \frac{1}{2} \sum_{j=1}^n \left( y_j - f_{x_j}(w) \right)^2\]and its gradient with respect to any one weight becomes:
\[\nabla L(w) \vert_{\text{one coordinate}} = - \sum_{j=1}^n \frac{\partial f_{x_j}(w)}{\partial w} \left( y_j - u_j \right) .\]Therefore, the dynamics of any one output label – which, in general, depends on all the weights – can be calculated by summing over the partial derivatives over all the weights:
\[\begin{aligned} \frac{du_i}{dt} &= \sum_w \frac{\partial u_i}{\partial w} \frac{dw}{dt} \\ & = \sum_w \frac{\partial f_{x_i}(w)}{\partial w} \left( \sum_{j=1}^n \frac{\partial f_{x_j}(w)}{\partial w} \left( y_j - u_j \right) \right) \\ &= \sum_{j=1}^n \Big\lang \frac{\partial f_{x_i}(w)}{\partial w}, \frac{\partial f_{x_j}(w)}{\partial w} \Big\rang \left(y_j - u_j \right) \\ &= \sum_{j=1}^n H_{ij} (y_j - u_j) , \end{aligned}\]where in the last step we switched the orders of summation, and defined:
\[H_{ij} := \Big\lang \frac{\partial f_{x_i}(w)}{\partial w}, \frac{\partial f_{x_j}(w)}{\partial w} \Big\rang = \sum_w \frac{\partial f_{x_i}(w)}{\partial w} \frac{\partial f_{x_j}(w)}{\partial w} .\]We have used angular brackets to denote dot products. In the case of an infinite number of parameters, the same relation holds. But we have to replace summations by expectations over a measure (and perform additional algebra book-keeping, so let’s just take it as true).
Once again, we make several remarks:
-
Observe that the dynamics is very similar in appearance to that of a linear model! in vector form, we get the evolution of all $n$ labels as
\[\frac{du}{dt} = H_t (y - u)\]where $H_t$ is an $n \times n$ matrix governing the dynamics.
-
But! There is a crucial twist! The governing matrix $H_t$ is no longer constant: it depends on the current set of weights $w$, and therefore is a function of time — hence the really pesky subscript $t$. This also means that the ODE is no longer linear; $H_t$ interacts with $u(t)$, and therefore the picture is far more complex.
-
One can check that $H_t$ is symmetric and positive semi-definite; therefore, we can view the above equation as the dynamics induced by a (time-varying) kernel mapping. Moreover, the corresponding feature map is nothing but:
\[\phi : x \mapsto \frac{\partial f_{x}(w)}{\partial w }\]which can be viewed as the “tangent model” of $f$ at $w$. This is a long-winded explanation of the origin of the name “NTK” for the above analysis.
Wide networks exhibit linear model dynamics
The above calculations give us a mechanism to understand how (and under what conditions) gradient dynamics of general networks resemble those of linear models. Basically, our strategy will be as follows:
-
We will randomly initialize weights at $t=0$.
-
At $t=0$, we will prove that the corresponding NTK matrix, $H_0$, is full-rank and that its eigenvalues are bounded away from zero.
-
For large widths, we will show that $H_t \approx H_0$, i.e., the NTK matrix stays approximately constant. In particular, the dynamics always remains full rank.
Combining $1+2+3$ gives the overall proof. This proof appeared in Du et al.6 and the below derivations are adapted from this fantastic book 9.
Concretely, we consider two-layer networks with $m$ hidden neurons with twice-differentiable activations $\psi$ with bounded first and second derivatives. This again means that ReLU doesn’t count, but other analogous proofs can be derived for ReLUs; see6.
For ease of derivation, let us assume that the second layer weights are fixed and equal to $\pm 1$ chosen equally at random, and that we only train the first layer. This assumption may appear strange, but (a) all proofs will go through if we train both layers, and (b) the first layer weights are really the harder ones in terms of theoretical analysis. (Exercise: Show that if we flip things around and train only the second layer, then really we are fitting a linear model to the data.)
Therefore, the model assumes the form:
\[f_x(w) = \frac{1}{\sqrt{m}} \sum_{r=1}^m a_r \psi(\langle w_r, x \rangle) .\]where $a_r = \pm 1$ and the scaling $\frac{1}{\sqrt{m}}$ is chosen to make the algebra below nice. (Somewhat curiously, this exact scaling turns out to be crucial, and we will revisit this point later.)
We initialize all weights $w_1(0), w_2(0), \ldots, w_r(0)$ according to a standard normal distribution. In neural network Since we are only using 2-layer feedforward networks, the gradient at time $t=0$ becomes:
\[\frac{\partial f_{x_i}(w(0))}{\partial w_r} = \frac{1}{\sqrt{m}} a_r x_i \psi'( \langle w_r(0), x_i \rangle )\]with respect to the weights of the $r^{th}$ neuron. As per our above derivation, at time $t=0$, we get that the NTK has entries:
\[\begin{aligned} [H(0)]_{ij} &= \Big\lang \frac{\partial f_{x_i}}{\partial w_r}, \frac{\partial f_{x_j}}{\partial w_r} \Big\rang \\ &= x_i^T x_j\Big[ \frac{1}{m} \sum_{r=1}^m a_r^2 \psi'( \langle w_r(0), x_i \rangle ) \psi'( \langle w_r(0), x_j \rangle ) \Big] \end{aligned}\]There is quite a bit to parse here. The main point here is to note that each entry of $H(0)$ is the average of $m$ random variables whose expectation equals:
\[x_i^T x_j \mathbb{E}_{w \sim \mathcal{N}(0,I)} \psi'(x_i^T w) \psi'(x_j^T w) := H^*_{ij}.\]In other words, if we had infinitely many neurons in the hidden layer then the NTK at time $t=0$ would equal its expected value, given by the matrix $H^$. (Exercise: It is not hard to check that for $m = \Omega(n)$ and for data in general position, $H^$ is full rank; prove this.)
Our first theoretical result will be a bound on the width of the network that ensures that $H(0)$ and $H^*$ are close.
Theorem Fix $\varepsilon >0$. Then, with high probability we have
\[\lVert H(0) - H^* \rVert_2 \leq \varepsilon\]provided the hidden layer has at least
\[m \geq \tilde{O} \left( \frac{n^4}{\varepsilon^2} \right)\]neurons.
Our second theoretical result will be a width bound that ensures that $H(t)$ remains close to $H(0)$ throughout training.
Theorem Suppose that $y_i = \pm 1$ and $u_i(\tau)$ remains bounded throughout training, i.e., for $0 \leq \tau < t$. Fix $\varepsilon >0$. Then, with high probability we have
\[\lVert H(0) - H^* \rVert_2 \leq \varepsilon\]provided the hidden layer has at least
\[m \geq \tilde{O} \left( \frac{n^6 t^2}{\varepsilon^2} \right)\]neurons.
Before providing proofs of the above statements, let us make several more remarks.
-
The above results show that the width requirement scales polynomially with the number of samples. (In fact, it is a rather high degree polynomial.) Subsequent works have tightened this dependence; these10 papers11 were able to achieve a quadratic scaling of $m = \tilde{O}(n^2)$ hidden neurons for GD to provably succeed. As far as I know, the current best bound is sub-quadratic ($O(n^{\frac{3}{2}})$), using similar arguments as above; see here12.
-
The above derivation is silent on the dimension and the geometry of the input data. If we assume additional structure on the data, we can improve the dependence to $O(nd)$; see our paper13. However, the big-oh here hides several data-dependent constants that could become polynomially large themselves.
-
For $L$-layer networks, the best available bounds are rather weak; widths need to scale as $m = \text{poly}(n, L)$. See here7 and here14.
Lazy training
** (Complete) **
Proofs
** (COMPLETE) **.
-
H. Li, Z. Xu, G. Taylor, C. Studer, T. Goldstein, Visualizing the Loss Landscape of Neural Nets, 2018. ↩︎
-
M. Hardt and T. Ma, Identity Matters in Deep Learning, 2017. ↩︎
-
H Daneshmand, A Joudaki, F Bach, Batch normalization orthogonalizes representations in deep random networks, 2021. ↩︎
-
Z. Li and S. Arora, An exponential learning rate schedule for deep learning, 2019. ↩︎
-
A. Jacot, F. Gabriel. C. Hongler, Neural Tangent Kernel: Convergence and Generalization in Neural Networks, 2018. ↩︎
-
S. Du, X. Zhai, B. Poczos, A. Singh, Gradient Descent Provably Optimizes Over-parameterized Neural Networks, 2019. ↩︎ ↩︎2 ↩︎3
-
Z. Allen-Zhu, Y. Li, Z. Song, Learning and Generalization in Overparameterized Neural Networks, Going Beyond Two Layers, 2019. ↩︎ ↩︎2
-
J. Lee, L. Xiao, S. Schoenholz, Y. Bahri, R. Novak, J. Sohl-Dickstein, J. Pennington, Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent, 2019. ↩︎
-
R. Arora, S. Arora, J. Bruna. N. Cohen, S. Du. R. Ge, S. Gunasekar, C. Jin, J. Lee, T. Ma, B. Neyshabur, Z. Song, Theory of Deep Learning, 2021. ↩︎
-
S. Oymak, M. Soltanolkotabi, Overparameterized Nonlinear Learning: Gradient Descent Takes the Shortest Path?, 2019. ↩︎
-
Z. Song and X. Yang, Over-parametrization for Learning and Generalization in Two-Layer Neural Networks, 2020. ↩︎
-
C. Song, A. Ramezani-Kebrya, T. Pethick, A. Eftekhari, V. Cevher, Subquadratic Overparameterization for Shallow Neural Networks, 2021. ↩︎
-
T. Nguyen, R. Wong, C. Hegde, Benefits of Jointly Training Autoencoders: An Improved Neural Tangent Kernel Analysis, 2020. ↩︎
-
D. Zou, Y. Cao, D. Zhou, Q. Gu, Gradient descent optimizes over-parameterized deep ReLU networks, 2020. ↩︎